LayerOne is an information security conference in LA which hosts one of the more enjoyable CTFs that I’ve participated in. This is the third in a series of a few post I am writing which goes over the solution of some of the CTF challenges. This post covers Web challenges.
The Challenges
This post goes over 5 separate challenges and attempts to solve them as intended. The category is called “Web” and it consists of the following five challenges:

I will go over these challenges in order, they are broken in to separate sections by name, search for the challenge name to find the write-up.
Front Page Ewws – 1 (25)
This challenge is pretty straight forward and the description comes with a pretty big hint. The description of the challenge is simply a URL: https://www.pwnzichain.com This is the same URL which is used in several other challenges.
The page renders pretty simply and looks like the following:
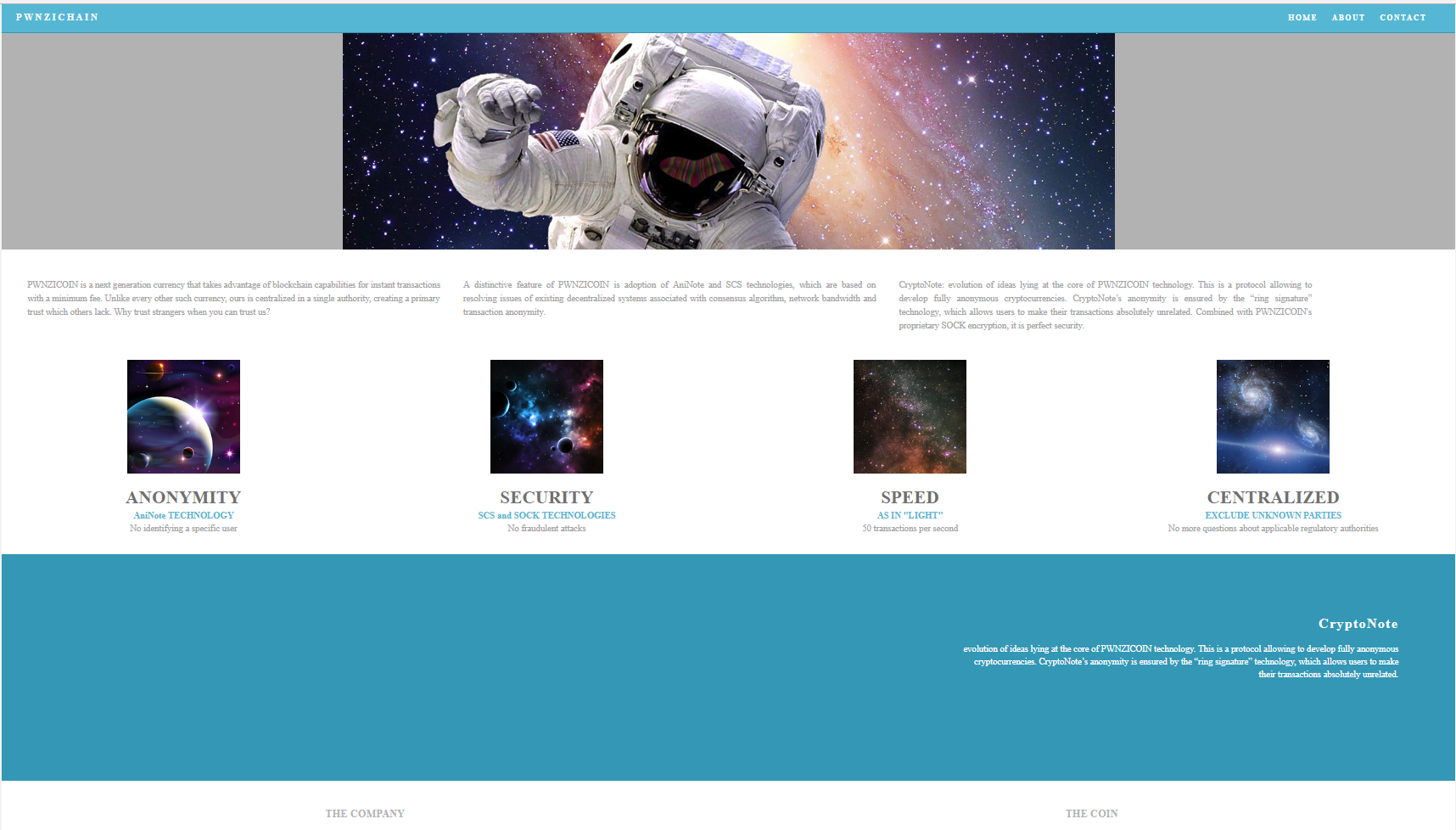
Nothing appeared to be very dynamic and a quick search did not find the word ‘flag’ anywhere. I decided to open up Chrome Developer Tools and did a quick search for the word ‘flag’ in the source code. The following snippet came up:

I very stupidly tried ‘Very simple’ as the password and it failed. I immediately went back to the site and kept searching. Turns out that it was just ‘Very Simple’ or all in lowercase (Thanks xcc!); can’t remember exactly what it was. Either way, it worked and we got the points which is all that matters.
They are coming… Part 1 (50)
The next challenge included the same link but a new description: “You have to crawl before you can run.”
The description and title here are both hints. One of the first things I do on web challenges is check for a “robots.txt” file. This file contains directories which are allowed or not allowed for crawlers (think the stuff that indexes for Google and other search engines). I called up https://www.pwnzichain.com/robots.txt and sure enough, here was the entry:

I followed the path and came across the flag!

Two down and three to go!
Front Page Ewws – 2 (100)
This challenge again came with no description. I loaded up Burp Suite and set it up as a proxy for my browser. I found some interesting headers which show that the site is hosted on AWS and is using an S3 bucket. I’ll cover what I looked through at first but it turned out to be unrelated to finding the flag; solution is towards the bottom of this section.
Some of the headers included the following:
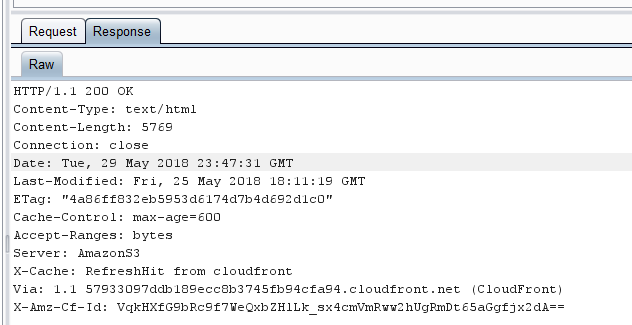
After poking around looking for S3 buckets for awhile I found what appeared to be a valid bucket
I started by using URLs like the following:
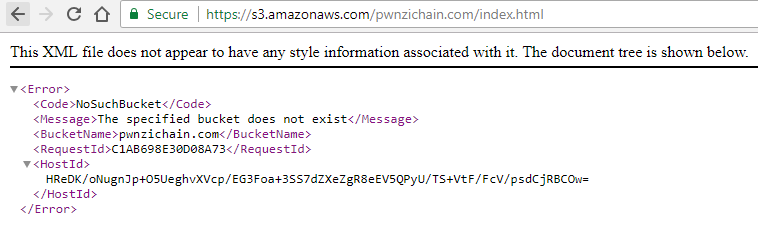
https://s3.amazonaws.com/pwnzichain.com/index.html
Which yielded results like the following, indicating the bucket did not appear to exist:
Eventually I stumbled across this message:
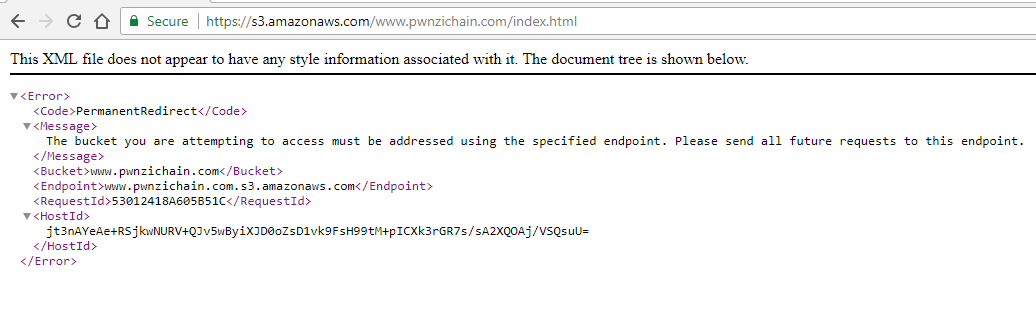
This indicates that I ought to use the endpoint URL: ‘www.pwnzichain.com.s3.amazonaws.com‘ instead of the one I was using which put the domain towards the end.
I tried that url and received a new error message ‘Access Denied’

This was progress, I added /index.html and was able to see the website, /robots.txt gave the same robots file, etc. It turns out none of this was really relevant but it was fun to learn a bit about S3 buckets.
A teammate went back to the main site and looked around and decided to dig further in to an entry style line:
<title>PWNZICHAIN</title> <link href="css/singlePageTemplate.css" rel="stylesheet" type="text/css"> <!--The following script tag downloads a font from the Adobe Edge Web Fonts server for use within the web page. We recommend that you do not modify it.--> <script>var __adobewebfontsappname__="dreamweaver"</script> <script src="http://use.edgefonts.net/source-sans-pro:n2:default.js" type="text/javascript"></script> <!-- HTML5 shim and Respond.js for IE8 support of HTML5 elements and media queries --> <!-- WARNING: Respond.js doesn't work if you view the page via file:// --> <!-- DocID: qevir.tbbtyr.pbz/bcra?vq=196YLPRmM0WVVBap-n9yahBd7ORIAb2p8 --> <!--[if lt IE 9]> <script src="https://oss.maxcdn.com/html5shiv/3.7.2/html5shiv.min.js"></script> <script src="https://oss.maxcdn.com/respond/1.4.2/respond.min.js"></script> <![endif]--> <style>
The line <!-- DocID: qevir.tbbtyr.pbz/bcra?vq=196YLPRmM0WVVBap-n9yahBd7ORIAb2p8 --> stuck out to me but it didn’t lead anywhere when i dropped it in the browser. However, my teammate looked in to it and thought it was a cipher.
A ‘ROT’ cipher is a rotation based cipher. The most common, rot-13 (aka the Ceasar Cipher), is often used in puzzles. It consists of rotating letters 13 characters (half of the alphabet). ‘a’ becomes ‘m’, ‘b’ becomes ‘n’, etc.
A quick way to validate this would be to rotate some key letters and see if they make sense. In this case, we can take the domain part of the apparent url – .pbz – and rotate that 13 characters.
a b c d e f g h i j k l m n o p q r s t u v w x y z
N O P Q R S T U V W X Y Z A B C D E F G H I J K L M
The above alphabet shows the alphabet split in half, to do a ROT13 quickly, just switch between the top and bottom lines for each character!.
p b z
becomes
c o m
The URL itself, when rotated through this, becomes: drive.google.com/open?id=196LYCEzZ0JIIOnc-a9lnuOq7BEVNo2c8
This takes us to a gif file! Which is great except it doesn’t appear to show the key anywhere :

However, if we open the file up in a text editor and scroll all the way to the end, we find good news!
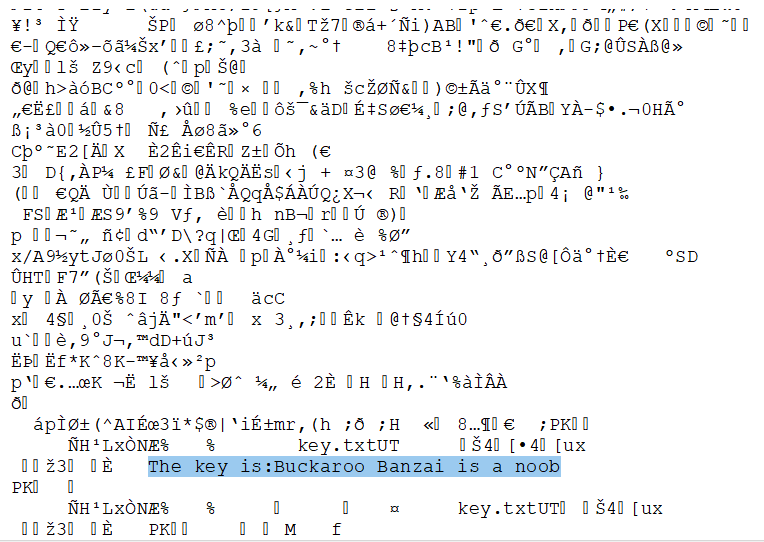
Flag obtained!
They are coming… Part 2 (150)
The next challenge comes with the following description: “History will not look kindly on those who allowed the robots to take over. But history may help you find the next flag.”
To start this challenge I started a dirbuster scan on https://www.pwnzichain.com Shortly after starting (just using the common.txt dictionary) I was able to find an interesting entry!
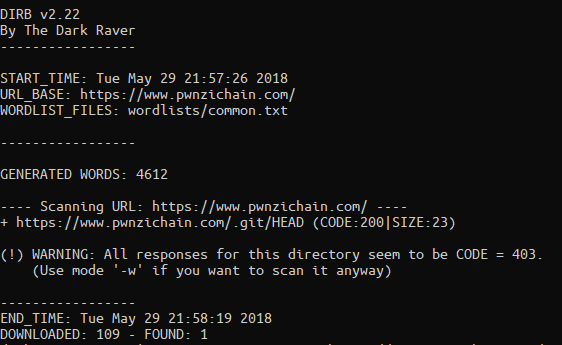
Excellent, it looks like they use Git for version control! Based on the description it seems likely that the flag might be in a previous commit of the site! I loaded up .git/HEAD and received a file which contained: “ref: refs/heads/master”
As I’m not a Git ninja I started googling around and found this great article which explained how to attack publicly exposed Git instances: https://en.internetwache.org/dont-publicly-expose-git-or-how-we-downloaded-your-websites-sourcecode-an-analysis-of-alexas-1m-28-07-2015/
The first thing I checked was if the file tree would list, it does not. The article then goes on to say that there are both standard files (which give things like hashes of commits, etc.) and then a directory of hashes which is of the format /.git/first_two_chars_of_hash/rest_of_hash I poked around and saw there was some information but it was very tedious to find.
Further down in the above article there is a link to a tool which can help to automatically reconstruct git repositories without directory traversal enabled. https://github.com/internetwache/GitTools I decided to try and run the ‘Dumper’ tool.
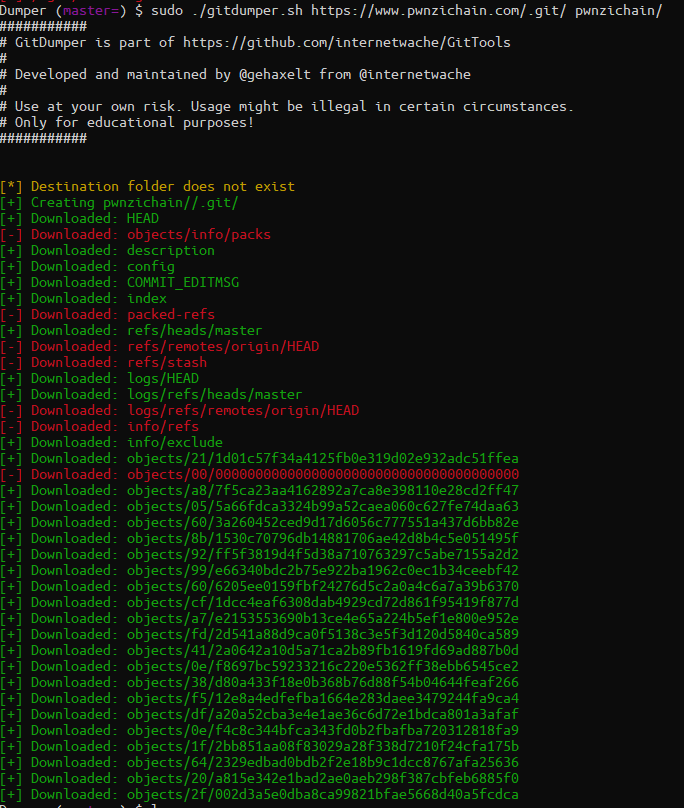
This generated the dump of the git repository. Now we need to extract the file artifacts to see if there are any flags in here! To do this, I decided to try the Extractor script.
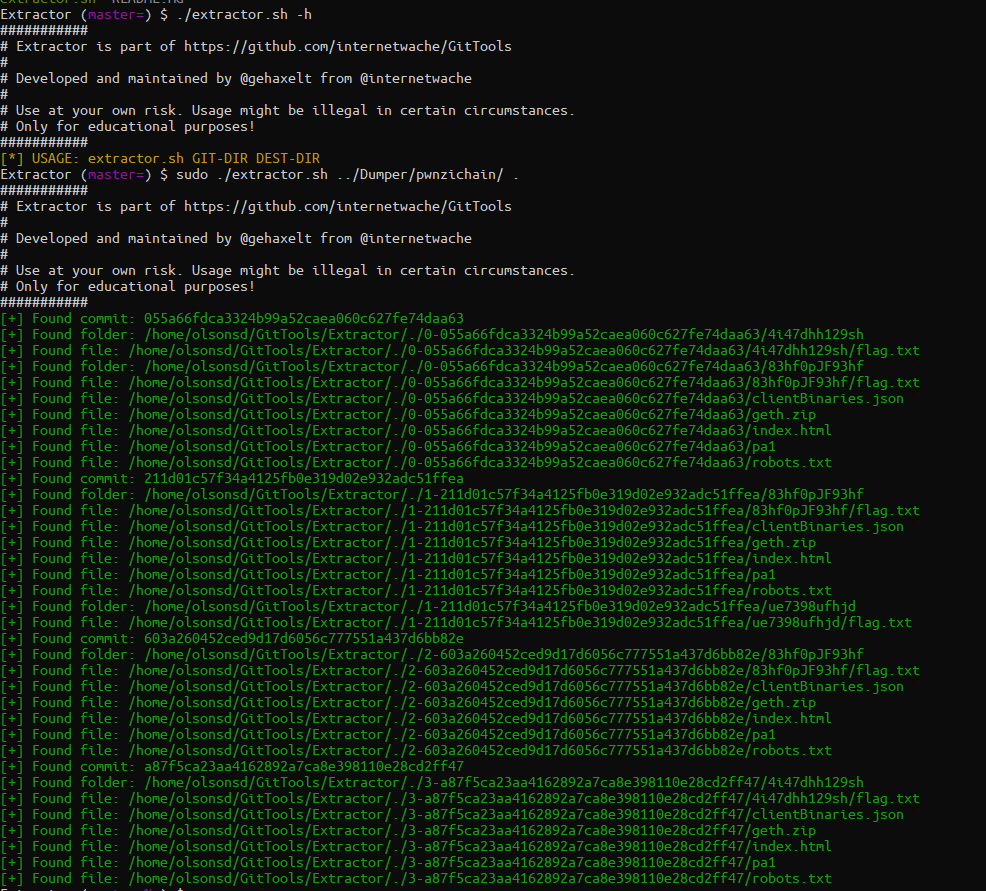
Excellent! I see multiple flag.txts in the results here and some other potentially useful files. I ran this shell script to see what’s in those flag.txt files! `find . -name “flag.txt” -exec cat {} \;
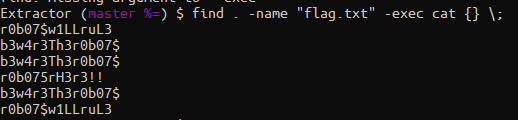
Flags!
They are coming… Part 3 (200)
The description of this last challenge in the series is “The robots have removed this flag from the system, but like the last challenge, history may be on your side.”
Since we have an extra flag from the previous challenge, we are set to try it on this challenge. Easy win since we found it with the last tool!
This is probably my second favorite section from the LayerOne CTF with the Cyber Kill Chain challenges being the most enjoyable for me.