Gobuster

TheColonial wrote a really cool tool called Gobuster which is similar to fierce but programmed in Go. I wanted to include it here because I tend to have better performance using this tool than fierce, by a LOT. Gobuster can be found on github here. There are a few issues to work out when setting up your Go environment but the official documentation should walk anyone through it and, if you have issues with the workspace creation, this StackOverflow article was useful. Essentially, make sure to build the workspace to the required specifications to compile the code. Once done you’re free to do something like ln -s /path/to/compiled/gobuster /path/to/recon/tools/gobuster to make it easier to access.
Scanning with Gobuster
Once completed you should grab a wordlist or use ones from the fierce directory we talked about earlier. When we try to run the script here’s our options:
abraxas@AttackVM:~/recon/gobuster$ ./gobuster -h Usage of ./gobuster: -P string Password for Basic Auth (dir mode only) -U string Username for Basic Auth (dir mode only) -a string Set the User-Agent string (dir mode only) -c string Cookies to use for the requests (dir mode only) -e Expanded mode, print full URLs -f Append a forward-slash to each directory request (dir mode only) -i Show IP addresses (dns mode only) -l Include the length of the body in the output (dir mode only) -m string Directory/File mode (dir) or DNS mode (dns) (default "dir") -n Don't print status codes -p string Proxy to use for requests [http(s)://host:port] (dir mode only) -q Don't print the banner and other noise -r Follow redirects -s string Positive status codes (dir mode only) (default "200,204,301,302,307") -t int Number of concurrent threads (default 10) -u string The target URL or Domain -v Verbose output (errors) -w string Path to the wordlist -x string File extension(s) to search for (dir mode only)
So we’ve got a good set of options to investigate. One of the important things to note is that this doesn’t strictly do DNS brute-forcing but also allows directory scanning/traversal. We won’t go in to this right now but will cover it at a later time in an article on Burp, DirBuster, and GoBuster.
The important flags from above, ignoring the directory mode options, are:
m– set this to ‘dns’ for nowi– if we want to see IPs from scanw– Path to the wordlistu– Target URL/Domain
Test Gobuster Scan
Let’s try this again on XKCD:
abraxas@AttackVM:~/recon/gobuster$ ./gobuster -u xkcd.com -w ../fierce-domain-scanner/hosts.txt -m dns -i Gobuster v1.1 OJ Reeves (@TheColonial) ===================================================== [+] Mode : dns [+] Url/Domain : xkcd.com [+] Threads : 10 [+] Wordlist : ../fierce-domain-scanner/hosts.txt ===================================================== Found: blog.xkcd.com [192.0.78.13, 192.0.78.12] Found: c.xkcd.com [107.6.98.34] Found: dynamic.xkcd.com [107.6.98.34] Found: es.xkcd.com [78.46.202.206] Found: forums.xkcd.com [104.196.146.194] Found: m.xkcd.com [104.156.81.67, 104.156.85.67, 23.235.33.67, 23.235.37.67] Found: irc.xkcd.com [107.6.89.242, 178.79.176.77, 208.87.120.111, 216.93.242.12, 66.228.37.186, 2a01:7e00::f03c:91ff:fedf:5bf1, 2001:4830:120:1::2, 2600:3c03::f03c:91ff:fedf:a1ab] Found: mobile.xkcd.com [104.156.85.67, 23.235.33.67, 23.235.37.67, 104.156.81.67] =====================================================
A few things to note:
- This scan, for me, is many times faster than fierce (it also defaults to 10 threads instead of fierce’s one thread)
- This scan appears to be more accurate. While it does catch more than fierce I still recommend running both tools more than once for optimal results
Tell me if you have the same experience! I’d love to benchmark these tools in a later post and knowing what experiences others have would be great as well.
EyeWitness
Now on to one of my favorite tools in the recon arsenal! EyeWitness is a tool by ChrisTruncer which takes a set of IP addresses or hostnames, attempts to screenshot them, and creates a nice report file!
First, we’ll clone the repository from here:
abraxas@AttackVM:~/recon git clone https://github.com/ChrisTruncer/EyeWitness
Once cloned and built we can run a -h on it and see our options. I’m excluding some of the text for brevity:
abraxas@AttackVM:~/recon/eyewitness$ ./EyeWitness.py -h
################################################################################
# EyeWitness #
################################################################################
usage: EyeWitness.py [--web] [--headless] [--rdp] [--vnc] [--all-protocols]
[-f Filename] [-x Filename.xml] [--single Single URL]
[--createtargets targetfilename.txt] [--no-dns]
[--timeout Timeout] [--jitter # of Seconds]
[--threads # of Threads] [-d Directory Name]
[--results Hosts Per Page] [--no-prompt]
[--user-agent User Agent] [--cycle User Agent Type]
[--difference Difference Threshold]
[--proxy-ip 127.0.0.1] [--proxy-port 8080]
[--show-selenium] [--resolve]
[--add-http-ports ADD_HTTP_PORTS]
[--add-https-ports ADD_HTTPS_PORTS] [--prepend-https]
[--vhost-name hostname] [--active-scan] [--resume ew.db]
The important things to note are the following:
- Use
--webwhen looking for web page headers and screenshots while using an OS with a GUI - Use –
-headlesswhen running from a GUI-less system,--webwill not work on a terminal-only system - Make sure your targets file (-f) is only IP addresses or URLs
Let’s take our XKCD scan we did earlier, modify it a bit for readability, and use this to prepare some data to run through EyeWitness.
Preparing EyeWitness Data
The command I will use to pull urls from GoBuster is this:
abraxas@AttackVM:~/recon/eyewitness$ ../gobuster/gobuster -w ../fierce-domain-scanner/hosts.txt -u xkcd.com -m dns > ../eyewitness/xkcd_urls.txt
If we cat that file we’ll see the following:
abraxas@AttackVM:~/recon/eyewitness$ cat xkcd_urls.txt Gobuster v1.1 OJ Reeves (@TheColonial) ===================================================== [+] Mode : dns [+] Url/Domain : xkcd.com [+] Threads : 10 [+] Wordlist : ../fierce-domain-scanner/hosts.txt ===================================================== Found: blog.xkcd.com Found: c.xkcd.com Found: dynamic.xkcd.com Found: es.xkcd.com Found: forums.xkcd.com Found: irc.xkcd.com Found: m.xkcd.com Found: mobile.xkcd.com =====================================================
This isn’t quite usable yet, we need the file to be in the form of: hostname <newline> hostname <newline>
Let’s write a quick bash command to extract this information for us:
cat xkcd_urls.txt | grep "Found" | cut -d" " -f2 > targets.txt
This will generate a targets.txt file from the xkcd_urls.txt for us, it looks like this:
abraxas@AttackVM:~/recon/eyewitness$ cat xkcd_urls.txt | grep "Found" | cut -d" " -f2 > targets.txt abraxas@AttackVM:~/recon/eyewitness$ cat targets.txt blog.xkcd.com c.xkcd.com dynamic.xkcd.com es.xkcd.com forums.xkcd.com irc.xkcd.com m.xkcd.com mobile.xkcd.com
This looks okay but I decided I wanted to write something a little more reusable so I don’t have to remember how to do that each time. Here is a bash script I wrote to handle that in a reusable way:
#!/bin/bash
read -p "Please input filename to extract hosts from: " filename
read -p "Input target name: " targetname
mkdir $targetname 2> /dev/null || true
result=$(cat $filename | grep "Found" | cut -d" " -f2 > $targetname/targets.txt)
echo "Success!"
echo "Created folder $targetname with extracted urls in 'targets.txt'"
This prompts for your input file, prompts for the name of the target, and then creates a directory for the target and saves your targets there! Pretty slick, right? Here’s what running it looks like:
abraxas@AttackVM:~/recon/eyewitness$ ./gob-extractor.sh Please input filename to extract hosts from: xkcd_urls.txt Input target name: xkcd Success! Created folder xkcd with extracted urls in 'targets.txt'
Now if we cat that file we should have the same desired output:
abraxas@AttackVM:~/recon/eyewitness$ cat xkcd/targets.txt blog.xkcd.com c.xkcd.com dynamic.xkcd.com es.xkcd.com forums.xkcd.com irc.xkcd.com m.xkcd.com mobile.xkcd.com
Success!
Using EyeWitness
Now that we have our targets file, lets see how this works and run the following:
./EyeWitness.py --headless -f xkcd/targets.txt -d xkcd_report
This returns the following:
################################################################################
# EyeWitness #
################################################################################
Starting Web Requests (8 Hosts)
Attempting to screenshot http://blog.xkcd.com
Attempting to screenshot http://c.xkcd.com
Attempting to screenshot http://dynamic.xkcd.com
Attempting to screenshot http://es.xkcd.com
Attempting to screenshot http://forums.xkcd.com
Attempting to screenshot http://irc.xkcd.com
Attempting to screenshot http://m.xkcd.com
Attempting to screenshot http://mobile.xkcd.com
Finished in 18.7914259434 seconds
[*] Done! Report written in the /home/abraxas/recon/eyewitness/xkcd_report folder!
Would you like to open the report now? [Y/n]
So it looks like it worked! I’ll SCP the files to my desktop and we can take a look at the results.
EyeWitness Reports
Without going in to too much detail, here’s some of the information EyeWitness returns back to us:
- Report Folder Contents
- Summary section
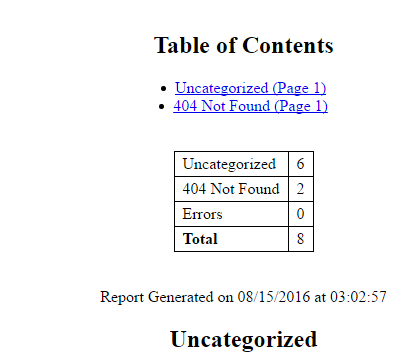
- Sample Report

As you can see, there’s some really good data – headers, source code, screenshots, and more.
It’s worth noting that, unlike our other scans/tools which are almost entirely passive and don’t touch target infrastructure, this will attempt to load each entry in our targets.txt file.
In our next article we will cover additional recon tools and strategies! As always, any criticism or feedback is welcome.